Abstract
Traditional methods for image-based 3D face reconstruction and
facial motion retargeting fit a 3D morphable model (3DMM) to the face, which
has limited modeling capacity and fail to generalize well to in-the-wild data.
Use of deformation transfer or multilinear tensor as a personalized 3DMM
for blendshape interpolation does not address the fact that facial expressions
result in different local and global skin deformations in different persons.
Moreover, existing methods learn a single albedo per user which is not enough
to capture the expression-specific skin reflectance variations. We propose an
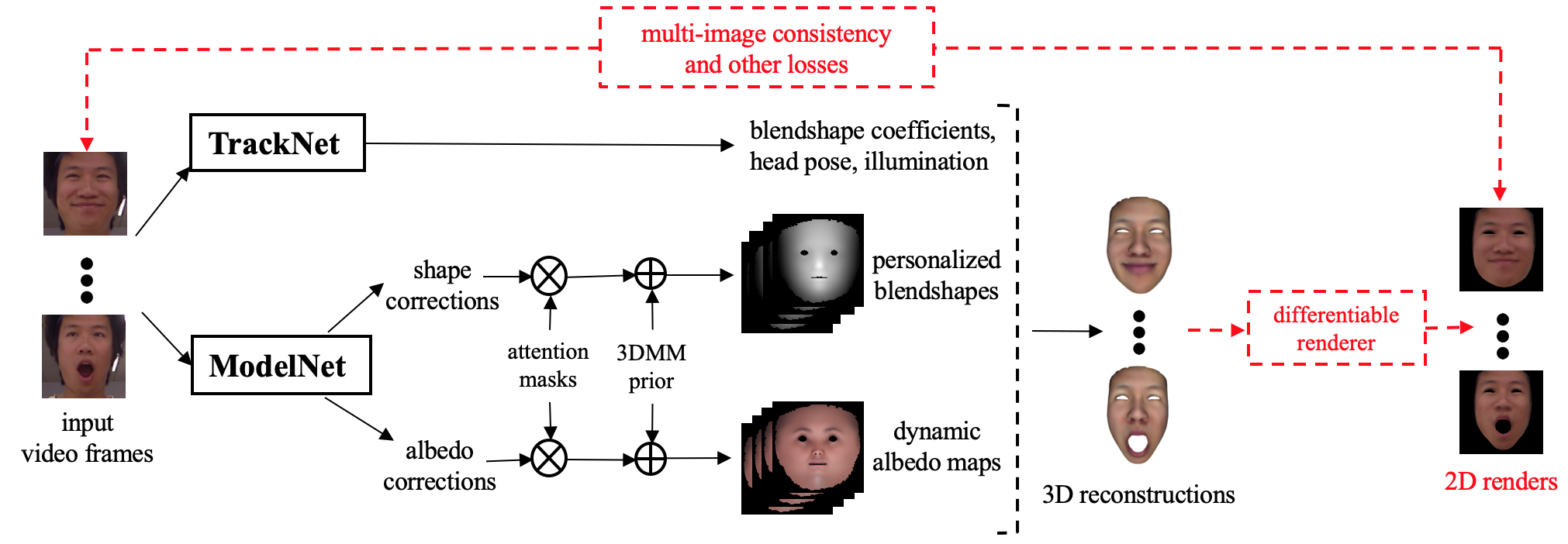
end-to-end framework that jointly learns a personalized face model per user and
per-frame facial motion parameters from a large corpus of in-the-wild videos
of user expressions. Specifically, we learn user-specific expression blendshapes
and dynamic (expression-specific) albedo maps by predicting personalized
corrections on top of a 3DMM prior. We introduce novel training constraints to ensure that
the corrected blendshapes retain their semantic meanings and the reconstructed
geometry is disentangled from the albedo. Experimental results show that our
personalization accurately captures fine-grained facial dynamics in a wide range
of conditions and efficiently decouples the learned face model from facial motion,
resulting in more accurate face reconstruction and facial motion retargeting
compared to state-of-the-art methods.

