Abstract
We introduce a novel approach to generate diverse high fidelity texture maps for 3D human meshes in a semi-supervised setup.
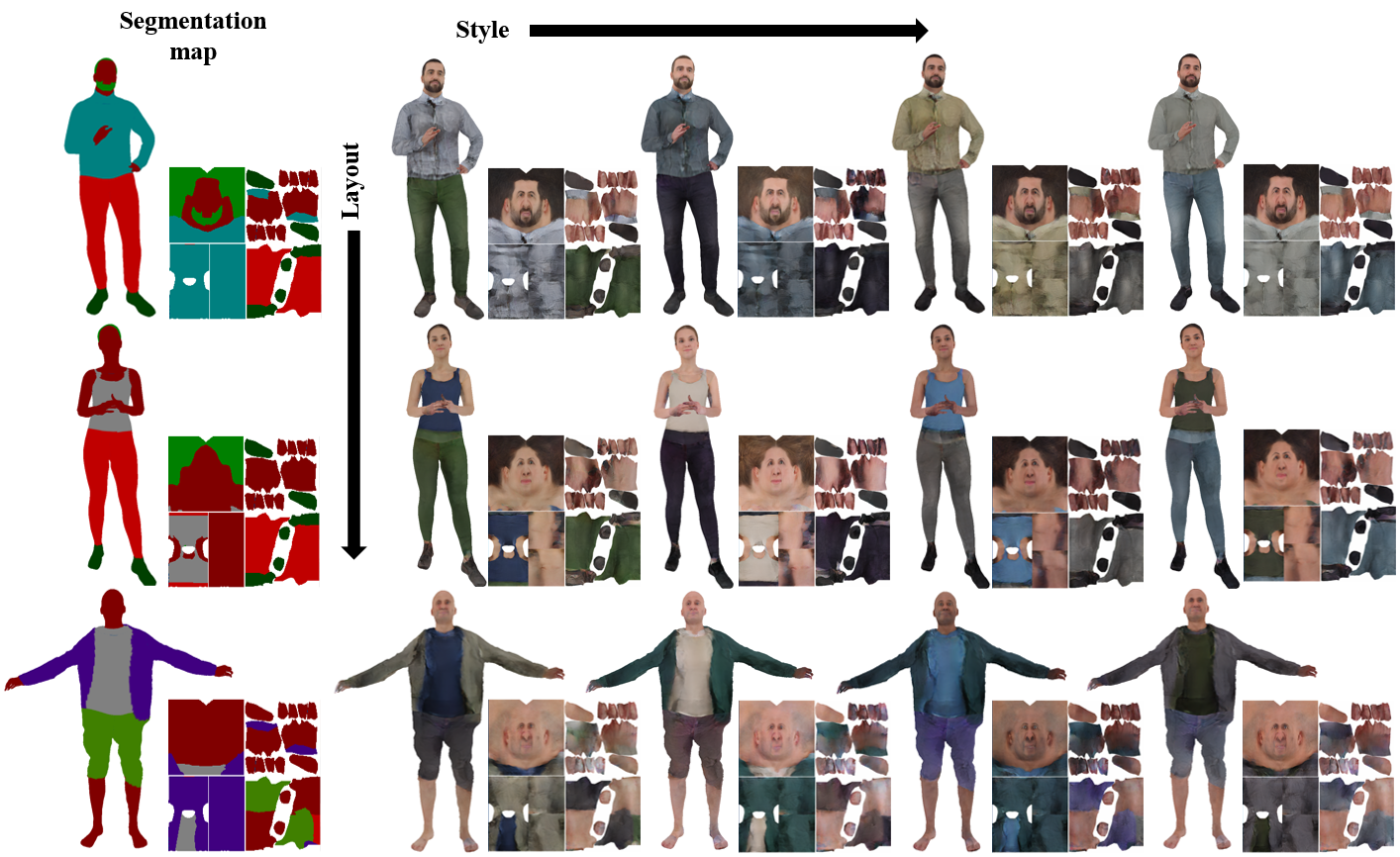
Given a segmentation mask defining the layout of the semantic regions in the texture map, our network generates high-resolution
textures with a variety of styles, that are then used for rendering purposes. To accomplish this task, we propose a
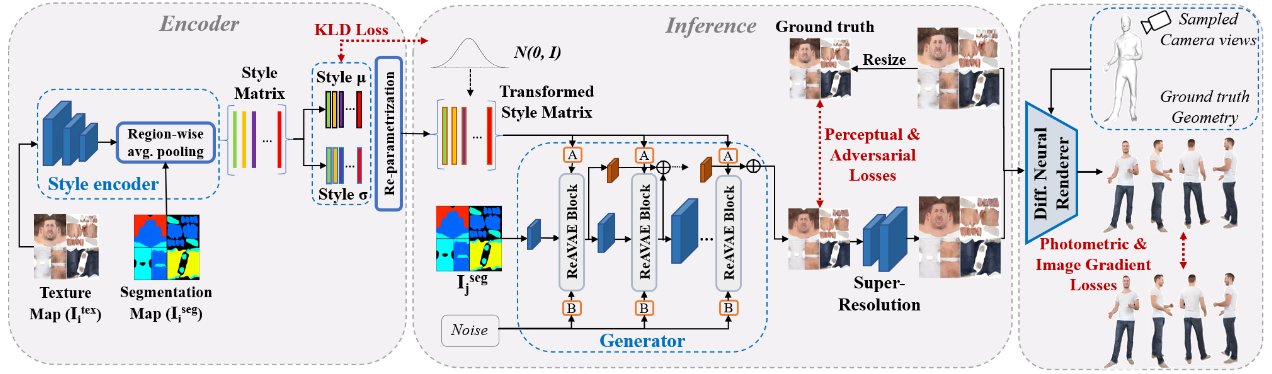
Region-adaptive Adversarial Variational AutoEncoder (ReAVAE) that learns the probability distribution of the style of each region
individually so that the style of the generated texture can be controlled by sampling from the region-specific distributions.
In addition, we introduce a data generation technique to augment our training set with data lifted from single-view RGB inputs.
Our training strategy allows the mixing of reference image styles with arbitrary styles for different regions, a property
which can be valuable for virtual try-on AR/VR applications. Experimental results show that our method synthesizes better texture maps
compared to prior work while enabling independent layout and style controllability.